My Backup Strategy
In over 2 decades of using a computer, I’ve managed to somehow avoid a substantial data loss. I’ve never had a disk failure or other catastrophe that took my data with it, and it was entirely luck. Like most, I never really gave much consideration to data backup. Earlier this year I decided to change that before it came back to bite me. This is my personal backup strategy.
My Server - My Problem.
As I’ve built out more self-hosted infrastructure and moved away from cloud services, I’ve become more reliant on my home server. Between Nextcloud, Paperless, Gitea, and plain old Samba, there isn’t very much I actually keep on my devices anymore. Everything either lives on the server, or is synced to it. I’m not worried about my laptop/phone being damaged/stolen and losing data - they’re just clients. Consequently, my backup strategy is centered around backing up a single server.
Restic
I’ve tried a lot of different applications for backups. My shortlist of requirements went something like this:
- FOSS
- Scriptable
- Encryption
- Incremental/Versioned
Borg and Restic were the 2 serious contenders for me, and in the end I went with Restic (Though I’d recommend either).
Restic works with the concepts of repositories (where data is backed up) and snapshots (point-in-time backups). These snapshots are incremental, which means only the changes since the last snapshot are backed up. If I were to delete/modify something today, but not notice it until after a few more snapshots have been created, I can still recover the file from those older snapshots.
For ease of management, I’ve broken my data up into what I’m calling datasets. These are just different collections of data that I back up into tagged snapshots. I’ve defined these datasets in my Ansible playbook:
restic_datasets:
- { name: 'photos', source: '{{ storage_path }}/userspace/photos' }
- { name: 'games', source: '{{ storage_path }}/userspace/games' }
- { name: 'software', source: '{{ storage_path }}/userspace/software' }
- { name: 'nextcloud', source: '{{ storage_path }}/appspace/nextcloud' }
- { name: 'paperless', source: '{{ storage_path }}/appspace/paperless' }
- { name: 'appdata', source: '{{ appdata_path }}', excludes: '{{ restic_appdata_exclude_file_path }}'}
The appdata dataset has an excludes file, which lists files and directories to ignore when backing up. Excluding the transcode directory for Jellyfin, as well as log directories in general, really helped cut down the total backup time:
{{ appdata_path }}/jellyfin/data/transcodes
{{ appdata_path }}/jellyfin/log
Restic supports many different backup location types. For the moment I’m backing up to another server in my house via sftp, and a Backblaze B2 bucket. This is known as a 3-2-1 Backup Strategy (3 total copies, 2 on-site, 1 off-site). I define these in my playbook as well:
restic_repos:
- { name: 'figgis', location: 'sftp:burritovoid@192.168.1.20:/mnt/storage/restic-vault'}
- { name: 'b2', location: '{{ restic_b2_location }}'}
Location
B2 storage, as of the time of writing, is $0.005/GB/month. This comes out to roughly $5/TB/month to store, which isn’t bad. However, this definitely isn’t the primary recovery method. A full data recovery from B2 (between the per GB download fee and per transaction fee) would cost me hundreds of dollars. This is my “The house burned down” option.
For the more common (and less catastrophic) recovery needs, I have an old gaming desktop running Debian and loaded with drives. It’s not the most power-efficient option, but it works. This would protect me from hardware failure on my main server, accidental deletions, etc.
Having the main and backup server on the same rack next to each other isn’t the most ideal configuration. In the event that my surge protection fails, or somehow the server rack was damaged, I’m left with only B2. In the future, I’d like to add a “regional” backup location (mom’s house).
The overall size of data I’m backing up hasn’t made this setup cost-prohibitive… yet. As my total data set continues to grow (or when I add another location), some datasets may get deprioritized to save on disk space.
Automation
My backups run nightly via a cron job. This is the template for the backup script:
#!/bin/bash
pingHC()
{
JOB=$1
curl -m 10 --retry 5 https://{{ healthcheck_io_host }}/ping/{{ restic_healthcheck_io_slug_id }}/restic-krieger-$JOB
}
cd /opt/restic-scripts
# B2 keys
export B2_ACCOUNT_ID={{ restic_b2_account_id }}
export B2_ACCOUNT_KEY={{ restic_b2_account_key }}
# restic repository password
export RESTIC_PASSWORD={{ restic_repo_password }}
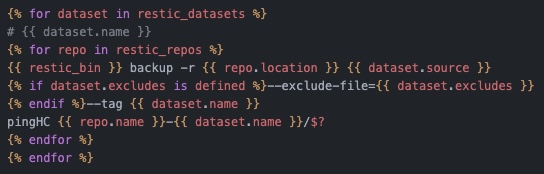
{% for dataset in restic_datasets %}
# {{ dataset.name }}
{% for repo in restic_repos %}
{{ restic_bin }} backup -r {{ repo.location }} {{ dataset.source }} {% if dataset.excludes is defined %}--exclude-file={{ dataset.excludes }} {% endif %}--tag {{ dataset.name }}
pingHC {{ repo.name }}-{{ dataset.name }}/$?
{% endfor %}
{% endfor %}
# Prune all datasets in repo
{% for repo in restic_repos %}
{{ restic_bin }} forget -r {{ repo.location }} \
--keep-daily {{ restic_prune_keep_daily }} \
--keep-weekly {{ restic_prune_keep_weekly }} \
--keep-monthly {{ restic_prune_keep_monthly }} \
{% for dataset in restic_datasets %}
--tag {{ dataset.name }}{% if not loop.last %} \
{% else %}
{% endif %}
{% endfor %}
pingHC {{ repo.name }}-restic-prune-nightly/$?
{% endfor %}
This template results in a restic backup for each dataset, in each backup location, tagged with the dataset’s name:
# photos
/usr/bin/restic backup -r sftp:burritovoid@192.168.1.20:/mnt/storage/restic-vault /mnt/storage/userspace/photos --tag photos
pingHC figgis-photos/$?
/usr/bin/restic backup -r b2:[bucketname] /mnt/storage/userspace/photos --tag photos
pingHC b2-photos/$?
I also prune the snapshots in each location to keep a specific number of daily, weekly, and monthly snapshots for each tag at a time:
# Prune all datasets in repo
/usr/bin/restic forget -r sftp:burritovoid@192.168.1.20:/mnt/storage/restic-vault \
--keep-daily 7 \
--keep-weekly 4 \
--keep-monthly 6 \
--tag photos \
--tag games \
--tag software \
--tag nextcloud \
--tag paperless \
--tag appdata
pingHC figgis-restic-prune-nightly/$?
Monitoring
The best backup plan is worthless if it doesn’t actually run. To make sure all of these jobs are running correctly, I’m using HealthChecks, a dead-man-switch style job monitoring tool. I’ve created a check for every dataset, each with it’s own unique URL. Those checks are configured to expect a ping every 24 hours, and will go into alarm status (Telegram notifications in my case) if they don’t. After each restic backup command is run, that URL is called to signal that the job has finished:
pingHC()
{
JOB=$1
curl -m 10 --retry 5 https://{{ healthcheck_io_host }}/ping/{{ restic_healthcheck_io_slug_id }}/restic-krieger-$JOB
}
...
pingHC {{ repo.name }}-{{ dataset.name }}/$?
Healthchecks supports signaling failures, which means the exit code can be appended to the request to immediately notify for a failure instead of waiting for the grace period to expire. ($? is a bash variable for the exit code of the last command run). I do this mostly as an indicator of why a job might be in alert. If it failed right away, something went wrong - it’s not just taking a long time.
Aside from knowing that the backups are running, it’s also important to know how to quickly recover data in the event that it’s needed, and that the data being backed up is what is expected. The only way to do this is to manually test a recovery. I do this by periodically restoring a backup directly to my desktop and verifying that it works as expected. This takes time, but it’s important.
SnapRAID
The notable exclusion from my Restic datasets is my media library. With upwards of 20TB, most of which exists in DVD/Bluray format in storage, it doesn’t make much sense to actually keep backups. Even with compression, I’d be looking at a significant increase (~10x) in disk space needed both locally and offsite. It’s just not worth it to me. However, hard drives do fail, and to help mitigate that I’m using SnapRAID.
RAID is not a backup
– Household bugs
Like a traditional RAID array, SnapRAID calculates and stores parity information for a collection of disks, but without the overhead. It works with mismatched disks of any size, and expansion is as simple as plugging in a new disk and modifying a config file. It’s not a backup, but it offers a much quicker recovery path from drive failure at the cost of a single additional hard drive (though you can add more parity drives for more resiliency).
SnapRAID doesn’t run in real-time like RAID - it needs to be run on a schedule, and it can take quite a while for larger disks. This makes it a poor choice for data that’s regularly changing, but perfect for something like a media library. I use Chronial’s snapraid-runner script to configure and run SnapRAID weekly, and report the status back to HealthChecks.
End
This isn’t the fanciest backup plan - it’s actually pretty boring. But for something like this, boring is good. I’ve only had to rely on my backups a couple of times after accidental deletions, and have yet to have a proper data loss event.
Here’s to another year of uneventful stability.